Discord Bot
https://github.com/ambocclusion/ComfyUI-SDXL-DiscordBot
I’ve been working on and off on a discord bot that lets you generate images using stable diffusion. the options for open source or off-the-shelf solutions are pretty limited so I opted to make one.
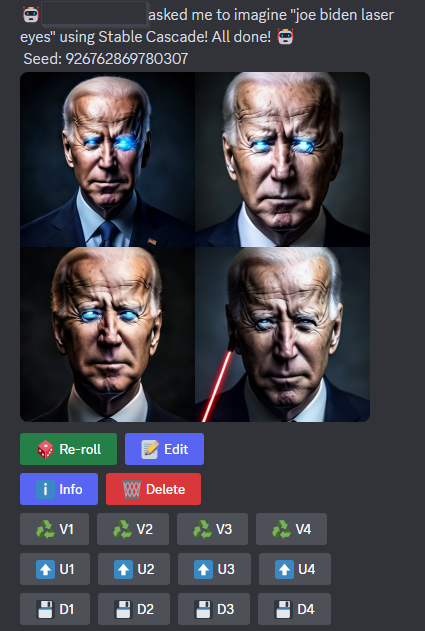
the main issues I ran into with other bots were that they were either limited by the backend they went with (likely automatic1111 webui) or aren’t regularly updated. I wanted something that allowed for modalities to be split into multiple commands to free up space for models and loras, and to make it easier for people who are uninformed to use.
comfyui backend
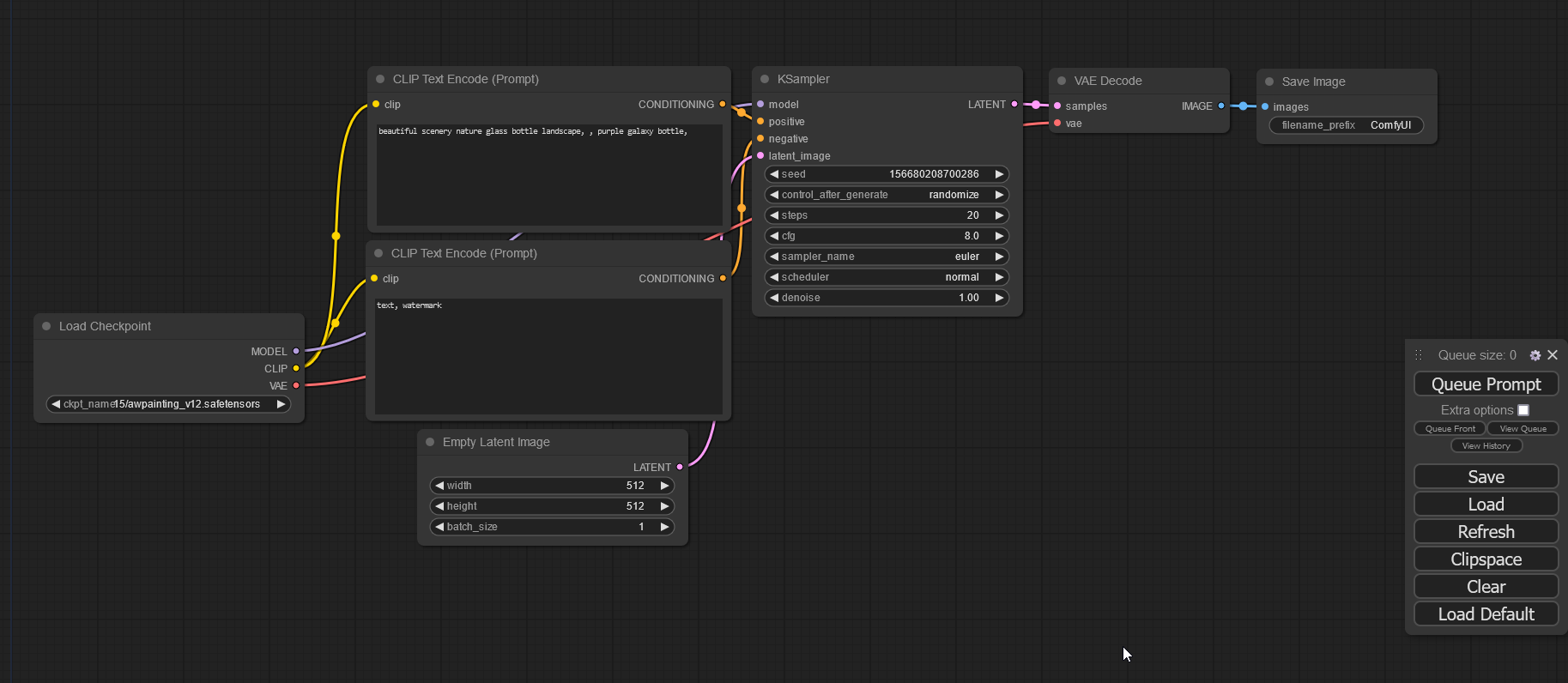 comfyui seemed like the best choice to lift the limitations imposed by things like a1111. I forked an existing project that utilized comfyui for local generation and stability.ai’s api for remote gens. since originally forking it it has retained very little of the original code. the biggest change was switching from sending json workflows to comfyui to using comfyscript to programmatically construct workflows before sending them to comfyui. this not only greatly reduced the complexity of the code but also unlocked a lot of cool possibilities. comfyui workflows are built up of logic nodes making it a really powerful visual scripting tool but it is lacking features like conditionals and for loops. this is where comfyscript comes in:
comfyui seemed like the best choice to lift the limitations imposed by things like a1111. I forked an existing project that utilized comfyui for local generation and stability.ai’s api for remote gens. since originally forking it it has retained very little of the original code. the biggest change was switching from sending json workflows to comfyui to using comfyscript to programmatically construct workflows before sending them to comfyui. this not only greatly reduced the complexity of the code but also unlocked a lot of cool possibilities. comfyui workflows are built up of logic nodes making it a really powerful visual scripting tool but it is lacking features like conditionals and for loops. this is where comfyscript comes in:
async def _do_video(params: ImageWorkflow, model_type: ModelType, loras: list[Lora]):
import PIL
with open(params.filename, "rb") as f:
image = PIL.Image.open(f)
width = image.width
height = image.height
padding = 0
if width / height <= 1:
padding = height // 2
image = LoadImage(params.filename)[0]
image, _ = ImagePadForOutpaint(image, padding, 0, padding, 0, 40)
model, clip_vision, vae = ImageOnlyCheckpointLoader(params.model)
model = VideoLinearCFGGuidance(model, params.min_cfg)
positive, negative, latent = SVDImg2vidConditioning(clip_vision, image, vae, 1024, 576, 25, params.motion, 8, params.augmentation)
latent = KSampler(model, params.seed, params.num_steps, params.cfg_scale, params.sampler, params.scheduler, positive, negative, latent, 1)
image2 = VAEDecode(latent, vae)
video = VHSVideoCombine(image2, 8, 0, 'final_output', 'image/gif', False, True, None, None)
preview = PreviewImage(image)
await preview._wait()
await video._wait()
results = video.wait()._output
final_video = PIL.Image.open(os.path.join(comfy_root_directory, "output", results['gifs'][0]['filename']))
return [final_video]
this will perform the same functions as a visual script would, and allows you to create really complex flows. previously this same kind of functionality was done in a script like this which was a nightmare for any kind of maintainability or extensibility. if you look at the other files in this part of the commit history you’ll also see that there were a lot of areas where things were hardcoded or just set to function a certain way and if any of that was changed it would break this script. glad to say this script is entirely gone now! a workflow like the above one would be represented in a json file like this and would be super inflexible.
as far as I know this discord bot is the most feature filled in terms of the modalities it supports out of the box. I’m not aware of any discord bot that supports most of the major stable diffusion releases from the past year and a half. I’ve come across discord bots that will do one model, or one that will provide video, but I’ve not seen anything that can be hosting locally that can do all of those things. also it does audio which is rad. thanks eigenpunk !!!!!!!
I’ll probably post more about this as I make more progress and add more features.
shout out to hot dad world life discord all my hommies